
CockroachDB makes data easier to manage by providing a strongly-consistent, highly-scalable, SQL interface that you can trust to be there when you need it. We’ve designed it to be a truly cloud-native, distributed SQL database that’s easy to operate in any environment you throw at it.
One such computing environment that has grown in popularity over the previous few years is Mesosphere’s DC/OS, a datacenter operating system built on top of Apache Mesos. DC/OS is an orchestration system for deploying and managing distributed applications across a cluster of machines as if they were a single pool of resources. DC/OS has both an open source and an enterprise version that gives you the ability to elastically scale your infrastructure on prem or in the cloud. It provides scheduling, resource allocation, service discovery, automatic recovery from failure, load balancing, and more, all with the goal of making it easier to manage your applications.
This makes CockroachDB and DC/OS a natural pair -- CockroachDB makes it easier to manage and scale mission-critical data, and DC/OS automates the management of CockroachDB, providing elastic scale, zero downtime, and hassle-free operations. In this post we’re going to take a look at how to combine the two by using the newly released framework for running CockroachDB on DC/OS.
Inside the CockroachDB DC/OS framework
The CockroachDB DC/OS framework is built using the dcos-commons SDK, which allows for creating incredibly resilient stateful frameworks without needing to write a whole bunch of new code. Instead, YAML and JSON configuration files are used to generate a framework that understands and can accommodate the needs of the underlying stateful application. The application (in this case, CockroachDB) can do its thing while the framework handles the hard problems around service discovery, storage management, scheduling, and deployment. As new improvements are added to the SDK, they’ll be automatically included in new releases of the CockroachDB framework.
Getting started with the framework (once you have a DC/OS cluster running) is as easy as choosing CockroachDB in DC/OS’s web interface or running dcos package install cockroachdb from the command line. This process can be customized if you’d like to change one of the settings presets, such as the number of CockroachDB processes to create, which machines they’re allowed to run on, or how much disk to allocate for them. Once you’ve done this, you should shortly see a CockroachDB service in the cluster with a handful of running processes:
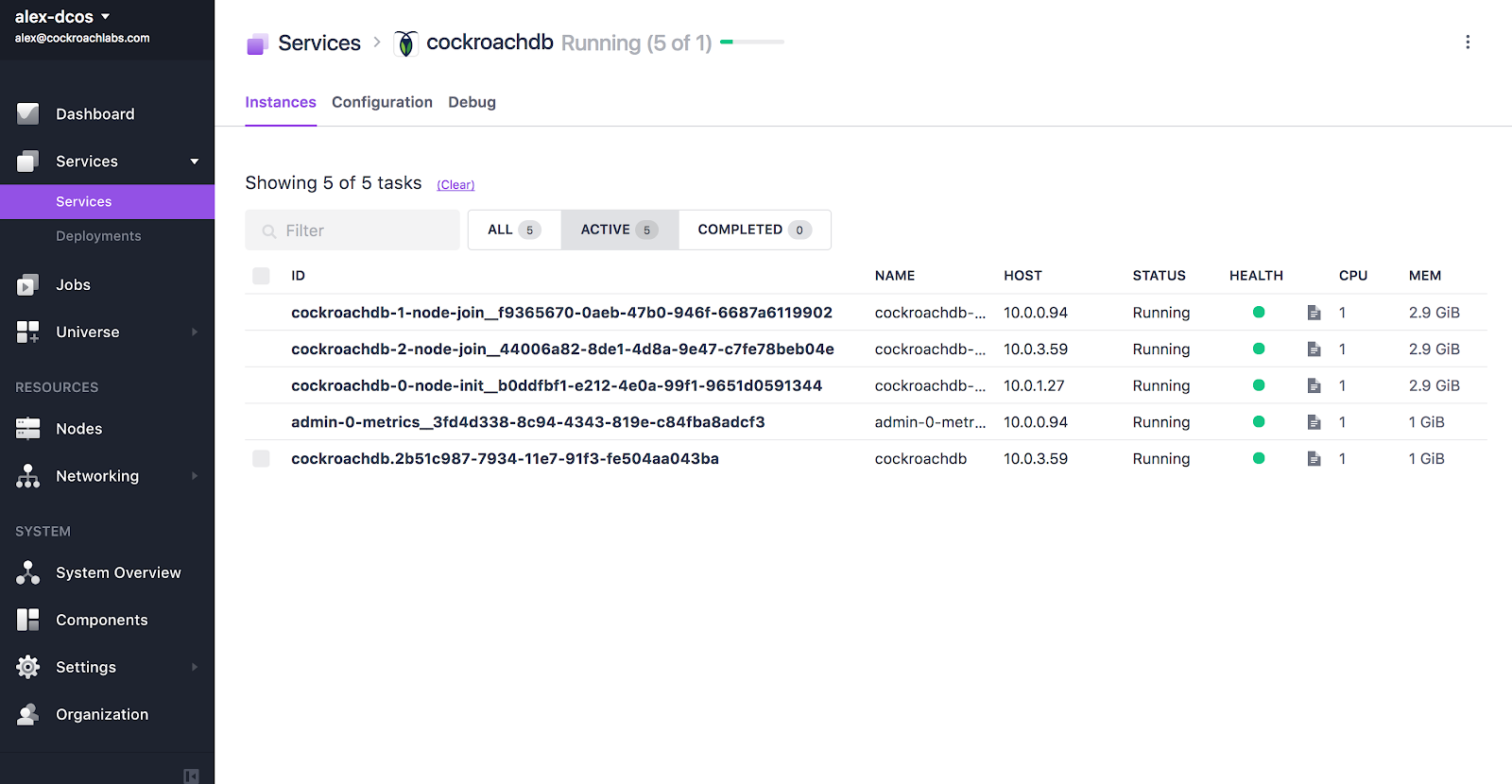
The first three tasks you see here are the actual running CockroachDB processes. The next task in the list is responsible for scraping metrics from the CockroachDB tasks. The final task is the framework scheduler, which is responsible for scheduling and managing the others.
While you might think that the scheduler isn’t doing much once the processes are up and running, in reality it’s actively ensuring that your database stays up and running. Health checks are constantly being run such that it will restart individual processes that are unhealthy. Individual machines are also being checked, and if one goes down, then the scheduler will move the CockroachDB task that was running on it to a healthy machine. And when you want to upgrade to a new version of CockroachDB, the scheduler will orchestrate the rolling upgrade process, restarting tasks one-by-one to avoid any user-visible downtime.
You can connect to the database from within the DC/OS cluster by simply talking to the pg.cockroachdb.l4lb.thisdcos.directory network endpoint as if it was a single process, using the PostgreSQL wire protocol. The network will handle finding a running process to talk to, and CockroachDB’s multi-active availability model ensures that your queries will get consistent responses no matter which process they’re talking to.
Beyond the normal operational capabilities of an orchestration system, the CockroachDB DC/OS framework has built-in support for backing up and restoring your database. Running a backup to AWS S3 is as simple as running dcos cockroachdb backup <database-name> <s3-bucket>, and restore works similarly. This makes it easy to run frequent regular backups to ensure that even in the case of a complete catastrophe, your data will be safe. While only S3 is supported for now, more backup destinations can be added as requested.
Where to go from here
While all the essentials are in place for running a production-ready deployment of CockroachDB on DC/OS, we’re sure there’s more that could be done to continue making it a better experience. We need your help to determine what’s most important. Try building an application using CockroachDB, running it on DC/OS, and providing feedback and patches to make the experience better for everyone!
Illustration by Ana Hill


